
Designed for
discovery
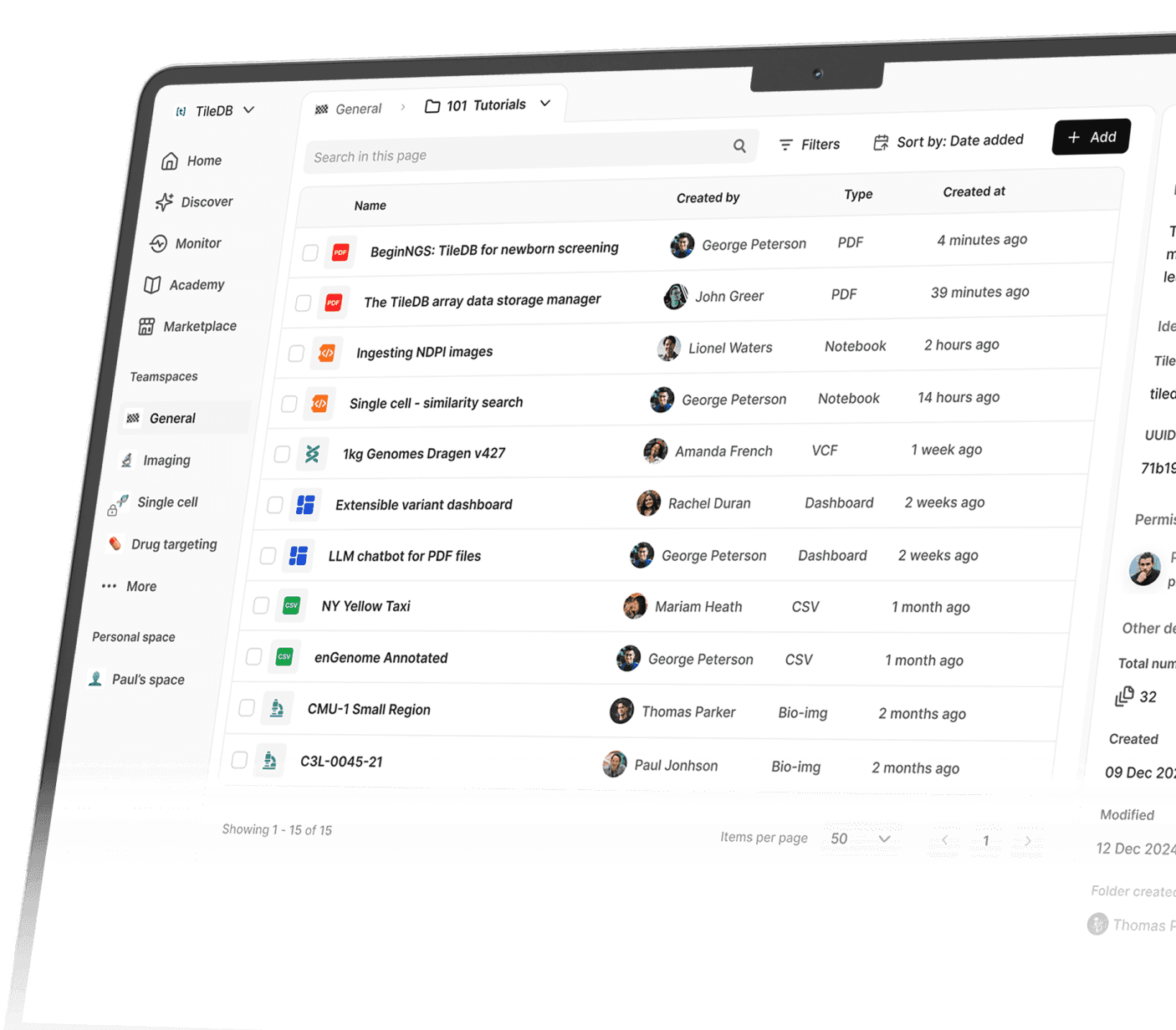
In TileDB, teams discover insights by easily managing and analyzing all their data, in one place, at scale.













A true multimodal database
With its pioneering array technology, TileDB enables you to discover breakthroughs by efficiently managing and analyzing all your data, from your frontier multiomics data to more common and everyday data.

Your unified data platform
Account for all your data, no matter how big, diverse and complex. Create folder hierarchies, attach meaningful descriptions and metadata and search holistically.
Tailored for the most challenging use cases
Support federated queries between namespaces and organizations within TileDB's trusted research environment.
Power variant analysis at biobank scale by combining an efficient storage format with the distributed power of the cloud.
Store petabyte-scale data cost-effectively while reducing costs by up to 97% compared to file-based approaches.
Run complex variant queries and turn around in hours that once took days.
The TileDB value
Data infrastructure
An elegant, data platform that easily consolidates diverse formats to drive discovery
Performance
An array-powered serverless engine that scales to the most complex data use cases
Operational costs
Reduced total cost of operations with an array format optimized for storage and computing
Collaboration
Discovery
Simplified, comprehensive search across teams and organizations
Customer case studies
TileDB made it work
How Cellarity powers next generation drug discovery using single-cell data
"By reducing the data engineering burden, our ML and computational scientists can focus on the science."
Parul Bordia Doshi
Chief Data Officer

Parul Bordia Doshi
Chief Data Officer







Start your discovery journey today