

Recently we hosted a webinar where I delivered a deep dive into TileDB Embedded, the open-source storage engine that powers the TileDB Cloud universal database. I demonstrated many hands-on examples on how to use TileDB from Python, R and SQL, which can serve as a great onboarding session for new and existing TileDB users. Finally, I showed two new powerful TileDB features, namely attribute filter condition push-down and schema evolution.
Here is the video recording of the webinar. Brace yourselves, it is 1.5 hours (with Q&A) as it covers a lot of ground.
But do not fret, in this blog post I provide a nice gist and a form of an index, so that you can quickly locate the stuff that interests you the most.
Specifically, I summarize what I covered in the webinar, and provide links to the Jupyter notebooks I used. The links take you to a preview of the notebooks on TileDB Cloud. From there you can download and run them locally, no TileDB Cloud account is needed. Alternatively, you can launch them directly in TileDB Cloud. For that you will need to sign up, but doing so is free, no credit card is required and you get $10 in free credits — more than enough to run all the webinar examples… hundreds of times. The webinar, as well as the rest of this blog post, are focused 100% on the open-source TileDB Embedded.
Introduction & Why Arrays
This webinar is for you if:
You are interested in data storage fundamentals (e.g., layout, compression, IO, etc.)
You are tired of using many different inefficient (often domain-specific) data formats
You wish to efficiently store and access any kind of data from anywhere with any tool
TileDB Embedded is a fast C++ library that allows you to store and access any data as multi-dimensional arrays. I go to great lengths in the recording to explain how foundational arrays are for laying out data of any type and domain as a sequence of bytes in a 1-dimensional storage medium. Arrays allow you to manipulate the data layout and, therefore, optimize it for your access patterns, increasing the locality of the results on storage and thus maximizing IO performance.
The TileDB Embedded library is wrapped by numerous programming language APIs and is integrated with a broad set of SQL engines and data science tools. It also works very well on a large set of storage backends, being particularly optimized for object stores, such as AWS S3, Azure Blob Storage and Google Cloud Storage.

The Basics
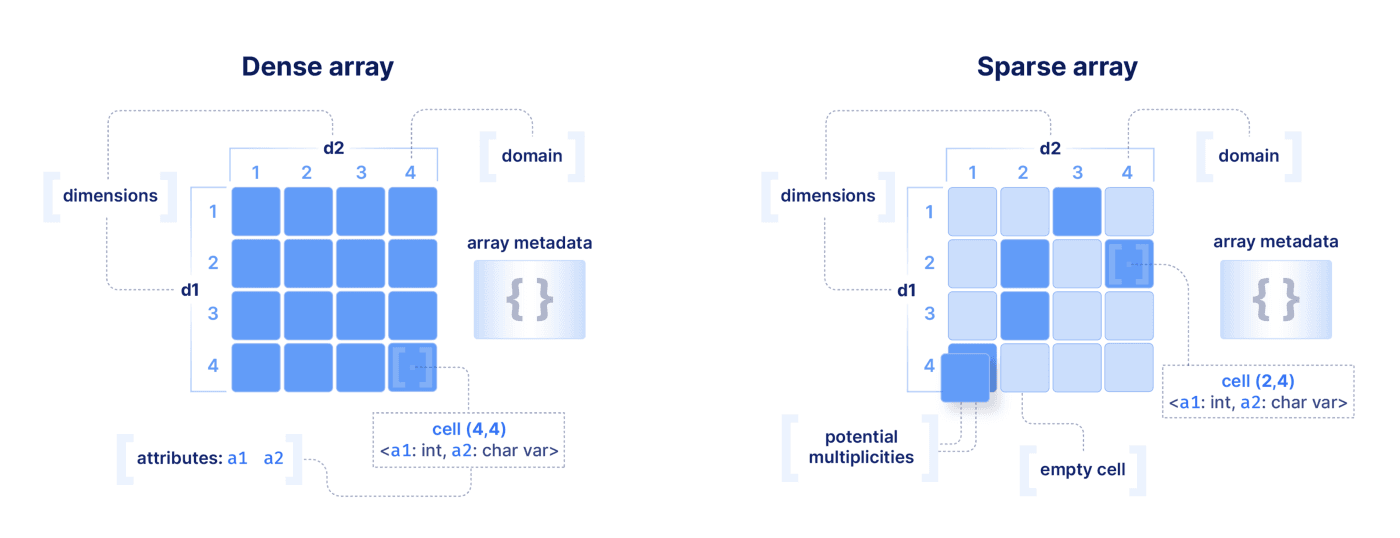
This section covers the data format of dense and sparse arrays, their differences and their basic write/read functionality. It also discusses features like groups, array metadata and variable-length attributes and dimensions. Finally, it explains how arrays subsume dataframes and how easy it is to use arrays on cloud object stores or any other backend.
Tiling & Layout
Tiling and cell layout are paramount to arrays. Here I discuss the main concepts, such as space tile extents, data tiles, tile capacity and the global cell order. Moreover, I cover tile filters such as compression, encryption and checksums.
Advanced Internal Mechanics
This section delves into more advanced features of TileDB Embedded, such as versioning, time traveling, indexing, consolidation and vacuuming. It also introduces two new exciting features, namely attribute filtering push-down and schema evolution. Finally, it offers quick tips on writing and reading for boosting performance.
Work In Progress
Our team is very hard at work and numerous new features are coming up. Here is a small taste of what will appear in the upcoming releases.
TileDB vs. Others
This is by no means a full-fledged comparison of TileDB to other storage engines, but in this section I touched upon a quick qualitative comparison between TileDB and popular systems like HDF5, Zarr, Parquet and Delta Lake. We are always happy to benchmark TileDB with anything you have in mind, but please suggest data and queries, which we should always make public so that anyone can reproduce and/or rebut.
About the author

Stavros Papadopoulos
Founder and CEO, TileDB
Prior to founding TileDB, Inc. in February 2017, Dr. Stavros Papadopoulos was a Senior Research Scientist at the Intel Parallel Computing Lab, and a member of the Intel Science and Technology Center for Big Data at MIT CSAIL for three years. He also spent about two years as a Visiting Assistant Professor at the Department of Computer Science and Engineering of the Hong Kong University of Science and Technology (HKUST). Stavros received his PhD degree in Computer Science at HKUST under the supervision of Prof. Dimitris Papadias, and held a postdoc fellow position at the Chinese University of Hong Kong with Prof. Yufei Tao.
Meet the authors