

Table Of Contents:
Beyond the Bench: The Data Challenges and Opportunities in Life Sciences
How frontier data is driving innovation
What do you need for the right data platform?
Beyond the Bench: The Data Challenges and Opportunities in Life Sciences
Discovery in life sciences is all consuming and a labor of love: painstakingly slow, but incredibly important work to bring positive impact to human health.
Take drug discovery: The average cost of bringing a new drug to market is $2.9 B and takes 10-15 years—then a whopping 90% of drug candidates don't get approved. This high bar is only getting higher, as new drugs are required to outperform existing ones. The result is the number of drugs brought to market for every billion dollars spent is going down by half every nine years. Oh, and the life sciences industry is also facing unprecedented pricing pressures in today’s economic environment.
But even as we face these challenges, we’re barely scratching the surface for discovering new drugs. Today, FDA-approved drugs target only about 850 of the roughly 4,000-5,000 druggable targets in the human proteome. In short, the challenges and opportunities in this space are breathtaking. For life sciences orgs to seize these opportunities, they must find new paths to facilitate discovery—and frontier data could be the answer.

How frontier data is driving innovation
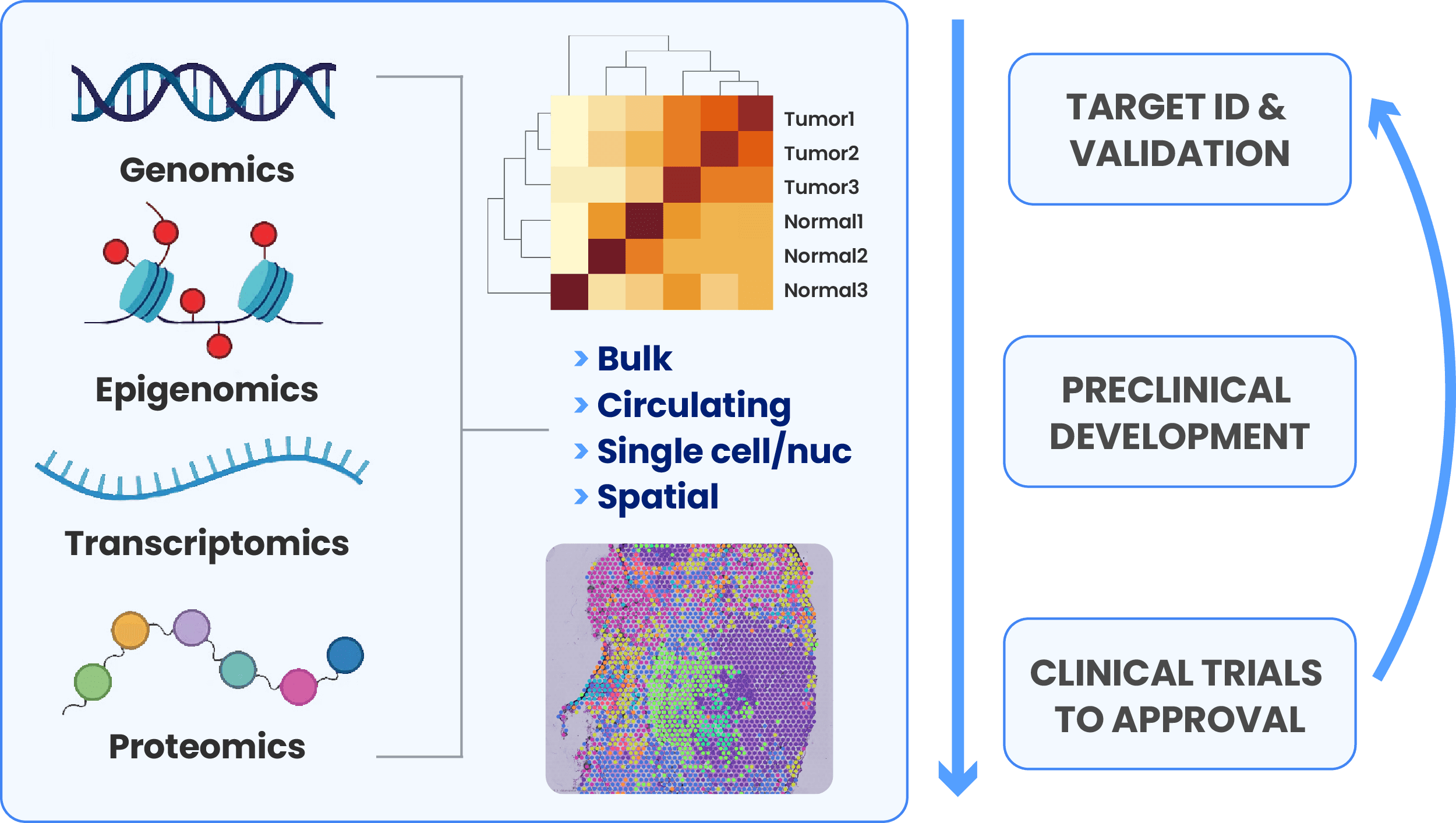
Frontier data like population genomics, bioimaging, proteomics, single-cell and spatial transcriptomics are powering modern research to improve discovery. By combining multiomics data sets with existing literature, public data banks and clinical data, scientists can uncover novel relationships, identify biomarkers, unravel complex disease mechanisms and ultimately drive precision medicine approaches in drug discovery and in the clinic.
Multimodal approaches, which include large-scale high dimensional multiomics data, are the next frontier where biopharma is hunting for new targets to expand treatment capabilities and improve patient outcomes. However, frontier data is often poorly structured and notoriously difficult to use, stressing the limits of general-purpose data and compute management.
As a result, this data needs to be managed and computed in ways that abstract it away from bench scientists—who now either need to learn how to code, or need to lean on research informatics teams in order to glean biologically meaningful insights. Collaboration between these teams is often difficult, suffering from backlogged data queries, workflow complexity and a lack of robust tools that scale and perform for both these groups. These inefficiencies can mean that life-changing drug and target discoveries are delayed or even missed altogether.
Complex data management approaches can also silo valuable data in multiple tools, storing the data in ways that make it hard to find and reuse. This has severe consequences for data scientists trying to action all relevant data to build ML models that speed drug discovery. Such models are better when they’re built on data from multiple modalities. This creates urgency to utilize organizational data together with public data to drive meaningful AI applications, so implementing FAIR data frameworks at source and through the analysis process is becoming a priority for biopharma. As combining frontier data together from multiple modalities becomes essential for discovery, life sciences organizations must figure out how to manage and compute all data together in a unified platform.
What do you need for the right data platform?
Finding the right platform for your organization’s unique needs is not easy. Current approaches to managing frontier data fall into two categories: buying general purpose data solutions or building DIY solutions using bespoke tools in house.
General purpose data solutions often struggle to model, store and analyze complex data modalities that do not fit into traditional tabular databases. Try fitting a VCF file or an image into a table. It will not work. At best, you can break up the data, or have your table store a pointer to a file. Given how these both create new issues, it is hard to say which is better.

On the other end of the spectrum, bespoke scientific solutions that cater to bench scientists face severe scalability limitations. Not built for scale, bespoke solutions often emphasize the UI at the expense of performance. This becomes especially evident when data volume surges. The massive gap complicates data infrastructure and hinders collaboration between research and data teams.
With countless point solutions available, teams need to select the necessary infrastructure to build support for bench scientists, bioinformaticians and data engineers who all need to collaborate to gather, catalog, govern and analyze all the complex data to reach the desired scientific breakthroughs.
This is a complex challenge, but with the right buying insights, you can find the best fit solution for your data needs. That’s why we put together a buying guide with key evaluation criteria to look for in a multimodal data platform. This guide draws on our interviews with data teams, research IT teams and scientists at leading biopharma companies to understand their current pain with multiomics data and multimodal approaches. We combine these insights with understanding based on our years of experience in the industry to help you find your ideal data solution. As you plan and budget for 2025, learn how to pick a data platform that will serve your needs not only today, but also into the future.
Get your copy of the buyer's guide here
Meet the authors