

Table Of Contents:
Summary of requirements
The TileDB data model
The TileDB data format
The TileDB storage engine
The TileDB community
A need for engines and APIs, not formats
A recent blog post by the OpenML community called “Finding a standard dataset format for machine learning” outlines a set of data format requirements for powering Machine Learning applications. The article articulates the challenges for storing machine learning data (that typically come into multiple forms such as images, audio, video, tables, etc.) in a common, shareable, and efficient data format. It also discusses the strengths and weaknesses of candidate formats such as Arrow/Feather, Parquet, SQLite, HDF5, and CSV. In this blog post we explain how TileDB addresses all these requirements overcoming the drawbacks of the other candidate formats, and take this opportunity to solicit feedback and contributions from the community.
TileDB started at MIT and Intel Labs as a research project in late 2014. In 2017 it was spun out into TileDB, Inc., a company that has since raised about $20M to further develop and maintain the project (see Series A announcement). TileDB consists of two offerings:
TileDB Embedded, a universal storage engine based on (dense and sparse) multi-dimensional arrays, which is an open-source (MIT license) C++ library that comes with numerous language APIs, as well as integrations with SQL engines and popular data science tooling.
TileDB Cloud, a commercial SaaS offering for planet-scale data sharing and serverless distributed computations.
TileDB Embedded addresses the OpenML data format challenges, all in an open-source, open-spec manner. TileDB Cloud is an orthogonal and complementary service for those that wish to further move the needle when it comes to planet-scale data sharing and compute, focusing on extreme ease of use, performance and cost savings.
In addition to showing how TileDB Embedded can power Machine Learning, we reveal important issues that have been plaguing not just Machine Learning applications, but also Databases and many other applications in various domains such as Geospatial, Genomics and more. Data scientists and analysts have been looking for a powerful “data format” to solve all their data management problems, often requiring it to be “simple” and “single-file”. We believe that it is time for the community to embrace a “data engine” approach which goes beyond just a data format. The goal should be to define and adopt clean and stable APIs that enable the constant technological advancement of data engines and underlying data formats.
Summary of requirements
The OpenML blog post outlines the following 17 data format requirements for ML applications.
- 1
There should be a standard way to represent specific types of data
- 2
The format should allow storing most (processed) machine learning datasets
- 3
A single internal data format to reduce maintenance both server-side and client-side
- 4
Support for storing sparse data
- 5
Support for storing binary blobs and vectors of different lengths
- 6
Support for metadata
- 7
Machine-readable schemas (in a specific language) that describe how a certain type of data is formatted
- 8
Support for multiple ‘resources’ (e.g. collections of files or multiple relational tables)
- 9
Version control, some way to see differences between versions
- 10
Detection of bitflip errors during storage or transmission
- 11
Support for object stores (e.g., S3, GCS, MinIO, etc.)
- 12
Support for batch data and data appending (streaming)
- 13
It should be useful for data storage and transmission
- 14
Fast reads/writes and efficient storage
- 15
Streaming read/writes, for easy conversion and memory efficiency
- 16
Parsers in various programming languages, including well-maintained and stable libraries
- 17
The format should be stable and fully maintained by an active community
The following sections explain point-by-point how TileDB satisfies these requirements via its:
multi-dimensional array data model
open-spec data format
open-source universal storage engine, along with its various APIs and integrations, and growing community
The TileDB data model
The TileDB data model satisfies requirements 1–6.
TileDB stores data as dense or sparse multi-dimensional arrays. The figure below demonstrates the data model, which is explained in detail in the TileDB docs.
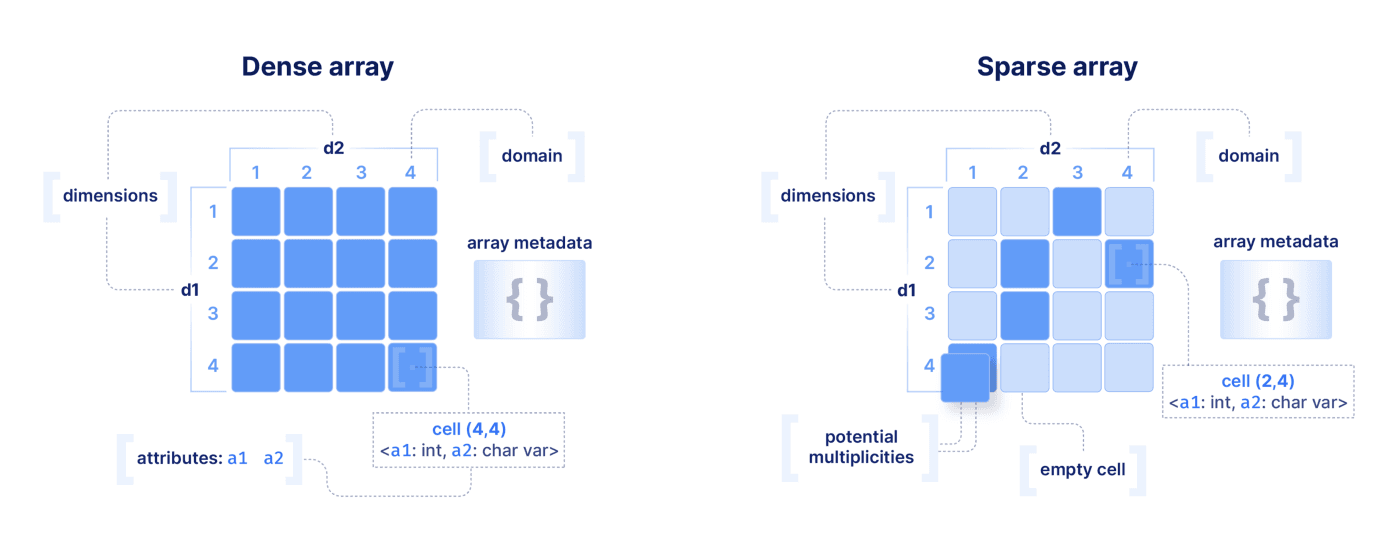
An array (either dense or sparse) consists of:
Dimensions: The dimensions d1 and d2 (figure above), along with their domains, orient a multi-dimensional space of cells. A tuple of dimension values, e.g., (4,4), is called the cell coordinates. There can be any number of dimensions in an array.
Attributes: In each cell in the logical layout, TileDB stores a tuple comprised of any number of attributes, each of any data type (fixed- or variable-sized). All cells must store tuples with the same set and type of attributes. In the figure, cell (4,4) stores an integer value for attribute a1 and a string value for a2, and similarly all other cells may have values for a1 and a2.
Array metadata: This is (typically small) key-value data associated with an array.
Axes labels: These are practically other (dense or sparse) arrays attached to each dimension, which facilitate slicing multi-dimensional ranges on conditions other than array positional indices.
TileDB handles both dense and sparse arrays in a unified way, but there are a few differences between the two to be aware of:
Cells in sparse arrays may be empty, whereas in dense arrays all cells must have a value; in dense arrays, “empty” cells must store a zero, a special fill value or be marked as null). Typically empty cells in sparse arrays are not materialized in the persistent format.
Dimensions in dense arrays must be homogeneous (i.e., must have the same data type) and support only integer data types. Dimensions in sparse arrays may be heterogeneous (i.e., may have different data types), and they support any data type, even real o rstring.
In sparse arrays, there may be multiplicities of cells (i.e., there may be more than one cells with the same coordinates), whereas this is not possible in dense arrays.
Some example applications that can benefit from multi-dimensional arrays are:
Any kind of tabular data as 1D dense vectors or ND sparse arrays
Any time-series data as 1D or ND (dense or sparse) arrays
Any point data (e.g., POIs) as 2D or 3D sparse arrays (e.g., LiDAR and AIS)
Population genomic variants (VCF collections) as 2D sparse arrays
Single-cell transcriptomic data as 2D dense or sparse arrays
Any large dense or sparse matrices used in Linear Algebra applications
Weather data (e.g., coming in NetCDF form) as labeled ND dense arrays
Satellite imaging (e.g., SAR) as 2D dense arrays or 3D temporal image stacks
Biomedical imaging as ND dense arrays
Audio (1D) or video (3D) applications
Oceanic data observations
Graphs as sparse adjacency matrices
At the data model definition level, here is how TileDB meets the first 6 OpenML requirements:
1. There should be a standard way to represent specific types of data
All types of data are uniformly modeled as ND dense or sparse arrays.
2. The format should allow storing most (processed) machine learning datasets
Any data type can be modeled as a ND dense or sparse array.
3. A single internal data format to reduce maintenance both server-side and client-side
Any data type can be modeled as a ND dense or sparse array.
4. Support for storing sparse data
The TileDB model natively supports sparse arrays.
5. Support for storing binary blobs and vectors of different lengths
The TileDB model allows storing var-sized attributes of any data type.
6. Support for metadata
Arbitrary key-value metadata (as well as axes labels) are part of the TileDB array model.
The TileDB data format
The TileDB data format satisfies requirements 7–12.
The TileDB data format implements the array data model described in the previous section and has the following high-level goals:
Efficient storage with support for compressors and other filters (e.g., encryption, checksums, etc.)
Efficient ND slicing
Efficient access on cloud object stores (in addition to other backends)
Support for data versioning
It is important to stress that the data format alone does not suffice; the format enables the storage engine implementation (discussed in the next section) to achieve the desirable features (e.g., time traveling) and performance (e.g., efficient IO on multiple storage backends).
TileDB employs a “multi-file” data format, organized in folder hierarchies (or prefix hierarchies for objects on the cloud). A multi-file format is absolutely necessary for supporting fast concurrent updates, especially on cloud object stores (e.g., S3) where all objects are immutable (i.e., to change a single byte in a TB-long object, you end up rewriting the entire TB-long object).
The entire TileDB format is open-source, open-spec and is described in detail here.
The TileDB data format meets the following OpenML requirements:
7. Machine-readable schemas (in a specific language) that describe how a certain type of data is formatted
This is achieved by the array schema file stored inside each array folder and the unified array data model.
8. Support for multiple ‘resources’ (e.g. collections of files or multiple relational tables)
This is achieved by the hierarchical folder organization using groups.
9. Version control, some way to see differences between versions
This is possible via the concept of immutable, time-stamped fragments.
10. Detection of bitflip errors during storage or transmission
TileDB supports a variety of filters that can be applied on a per data tile basis, including MD5 and SHA256 checksums.
11. Support for object stores (e.g., S3, GCS, MinIO, etc.)
The TileDB format is cloud-optimized, ideal for object stores such as S3, MinIO, GCS and Azure Blob Storage (among other backends).
12. Support for batch data and data appending (streaming)
This is supported via the concept of batched writes into immutable fragments anywhere in the array domain (which goes beyond just “appending”).
The TileDB storage engine
The TileDB storage engine satisfies requirements 13–16.
The TileDB format paves the way towards efficient data management, but alone it is not enough. A storage engine is necessary to implement the various features and achieve performance via parallelism, great engineering around the format use, and efficient interoperability with higher level compute layers.
Towards this end, we built a powerful C++ library with the following goals in mind:
Fast multi-threaded writes (from multiple input layouts)
Fast multi-threaded reads (into multiple output layouts)
Atomicity, concurrency and (eventual) consistency of interleaved reads and writes, following a multiple writer / multiple reader model without locking or coordination
Time-traveling
Consolidation and vacuuming
Numerous efficient APIs and integrations with a growing set of SQL engines and data science tools, adopting zero-copy techniques wherever possible
A modular and extensible design to support a growing set of storage backends (local disk, S3, GCS, HDFS, and more)
Backwards compatibility as the TileDB format gets improved with new versions
The core C++ library should be serverless!
The figure below shows the TileDB Embedded architecture. The core library is open-source and does everything in terms of data storage and access and exposes a C and C++ API. The rest of the APIs are efficiently built on top of those two APIs. The integrations with the SQL engines and other tools are done using these APIs and we carefully zero-copy wherever possible (i.e., we write the sliced results directly in the memory buffers exposed by the higher level applications, avoiding multiple data copies and thus boosting performance). We will soon publish our integration with Apache Arrow, so expect the TileDB integrations to grow. It is important to stress that we intentionally designed the library to be embedded and, therefore, serverless. That allows one to use it easily via the various APIs without spinning up clusters, but also to integrate with distributed systems (like Spark, Dask and Presto) if you wish extra scalability. TileDB Embedded along with its APIs and integrations are all open-source.

To see how TileDB Embedded works, check out the C, C++, Python, R, Java and Go examples, or the MariaDB, Spark, Dask, PDAL and GDAL integrations.
You can find the full documentation about the TileDB Embedded internal mechanics in our docs.
The requirements met by the TileDB storage engine are as follows:
13. It should be useful for data storage and transmission
This is due to the folder-based storage format, as well the fact that TileDB Embedded offers numerous APIs and integrations for efficiently slicing the data.
14. Fast reads/writes and efficient storage
This is due to the combination of the data format and the efficient TileDB Embedded storage engine implementation.
15. Streaming read/writes, for easy conversion and memory efficiency
These are all handled by the storage engine implementation.
16. Parsers in various programming languages, including well-maintained and stable libraries
Not just parsers, but instead a single super efficient C++ core implementation, along with numerous language APIs and integrations with popular SQL engines and data science tools.
The TileDB community
This section covers the last (17th) requirement.
TileDB Embedded is a fairly recent project, but the community around it is growing steadily. Every day we are surprised by the way users take advantage of TileDB’s functionality, and this is mainly due to the broad applicability of the array data model and numerous APIs and integrations we work hard to build and maintain. We very happily welcome contributions and we are serious about diversity and equal opportunity. We immediately respond to Github issues and our forum, whereas we also encourage users to submit feature requests that we are eager to include in our roadmap.
Everything described above is open-source, and it will continue to be. Although TileDB Embedded is currently governed by the TileDB, Inc. commercial entity, it makes zero business sense to close-source a data format and associated storage engine, especially when the project targets a broad community that includes users working in a variety of important scientific domains and is geared towards promoting technological and scientific innovation. Nevertheless, we are determined to take extra steps to help the TileDB user and developer community be protected in the future, in the event that they are unhappy with our organization and decide to independently evolve the project in a different fork:
- 1
We have been fully documenting every single function in the code since day one.
- 2
We maintain a human-readable format description here.
- 3
We continue to improve our docs and are in the process of publishing a series of blogs, tutorials and videos about the TileDB usage and internal mechanics.
- 4
We are documenting how the code is structured to help developers start contributing to the project.
The last requirement:
17. The format should be stable and fully maintained by an active community.
What is more important is for the format to be able to continuously improve and gracefully evolve to implement new features and embrace future technological advancements (e.g., innovation in cloud object stores or NVMe). Instead of being stable and inflexible, it must come with a fully maintained storage engine that provides backwards compatibility to support older format versions. Also the storage engine must have stable APIs, which should undergo smooth deprecation cycles when it is absolutely necessary to make a breaking API change. Our team is 100% committed to maintain the TileDB Embedded project, and to grow its user and developer community.
A need for engines and APIs, not formats
- 1
Problem #1: “Simple” or “single-file” formats. Take Parquet and ORC for tabular data, COG for geospatial imaging, VCF for genomic variants, LAZ for LiDAR point clouds, and I can go on and on. Any single-file format can be designed to be self-contained and awesome using domain knowledge and putting sufficient thought into it. The problems begin when updates, time-traveling, cloud storage and analysis on huge file collections crash the party. Single-file formats are simply a non-starter for object stores. Updates and time-traveling add inevitable complexity. Analysis on millions of files suffers from performance due to the lack of IO locality, and you quickly enter a metadata management hell. The above naturally gave rise to multi-file formats like Delta Lake, Zarr and of course TileDB.
- 2
Problem #2: Format specifications, ignoring the software implementation. Any data format, no matter how elegant and powerful, is not sufficient. Also mere format “parsers” are not enough either. In order to be able to extract extreme performance from a carefully designed data format, you need extreme engineering to build powerful software around it. If there is no storage engine around the format, or if that engine is not interoperable with many languages and tools, the burden falls on the users to rebuild from scratch that sophisticated engine, which is an enormous undertaking. For example, Zarr is originally built in Python and relies on Dask for parallelism (also written in Python). One needs to rewrite the entire storage engine from scratch in an efficient (e.g., multi-threaded) way to access Zarr data in C++, Java, Go, etc.
- 3
Problem #3: Format standards. Fixed formats cannot outlive innovation or what comes next. As an example, weather data is often stored in the NetCDF format, which is based on HDF5, a great single-file format that is not architected to work well on cloud object stores. Therefore, due to the need for cheap cloud storage, choosing the NetCDF format as a “standard” format for weather data was the wrong choice in retrospect, and now the community is shifting to other cloud-native formats such as Zarr and TileDB (e.g., see this nice article written by the UK Met Office on TileDB). Choosing a “standard” format hinders the efforts for innovation.
So what is the solution? The answer is actually simple. Look for engines and APIs, not formats. The engine should be tasked with building all the magic to make efficient use of the underlying data format, and interoperate with every language and tool. Also the engine must be responsible for extensibility (to add new features or support more storage backends) and backwards compatibility. The underlying data format should be able to evolve with the storage engine as well. In addition, the communities should work together to define standard APIs. There is a recent initiative for defining array API standards that looks promising (although currently limited to Python — theoretically, we can extend this to any language). By defining APIs we can allow anyone to design new formats and build new engines. It is through healthy and fair competition that technology can advance quickly.
TileDB Embedded is our embodiment of this solution, designed with the following goals in mind:
- 1
Design an effective open-spec data format allowing it to evolve in time
- 2
Build a powerful open-source storage engine around it in a fast language (e.g., C++)
- 3
Support numerous storage backends in an extendible way
- 4
Build numerous efficient language APIs on the core engine using zero-copy techniques
- 5
Use the APIs to integrate with SQL engines and data science tooling
- 6
Optionally push compute primitives down to the storage engine in a modular way
- 7
Help define and adopt standard APIs
We are excited to work with the ML community — and many others — to meet the evolving challenges of advanced data management and analysis. All the credit for the great work described above goes to our brilliant team, contributors, users and customers. If what you read here resonates with you, we encourage you to become contributors, follow us on Twitter and LinkedIn, post on our forum, request features, or simply drop us an email at [email protected]. Last but not least, we are looking to grow our team with more awesome people. See our open positions at https://ats.rippling.com/tiledb-careers/jobs and apply today!
About the author

Stavros Papadopoulos
Founder and CEO, TileDB
Prior to founding TileDB, Inc. in February 2017, Dr. Stavros Papadopoulos was a Senior Research Scientist at the Intel Parallel Computing Lab, and a member of the Intel Science and Technology Center for Big Data at MIT CSAIL for three years. He also spent about two years as a Visiting Assistant Professor at the Department of Computer Science and Engineering of the Hong Kong University of Science and Technology (HKUST). Stavros received his PhD degree in Computer Science at HKUST under the supervision of Prof. Dimitris Papadias, and held a postdoc fellow position at the Chinese University of Hong Kong with Prof. Yufei Tao.
Meet the authors