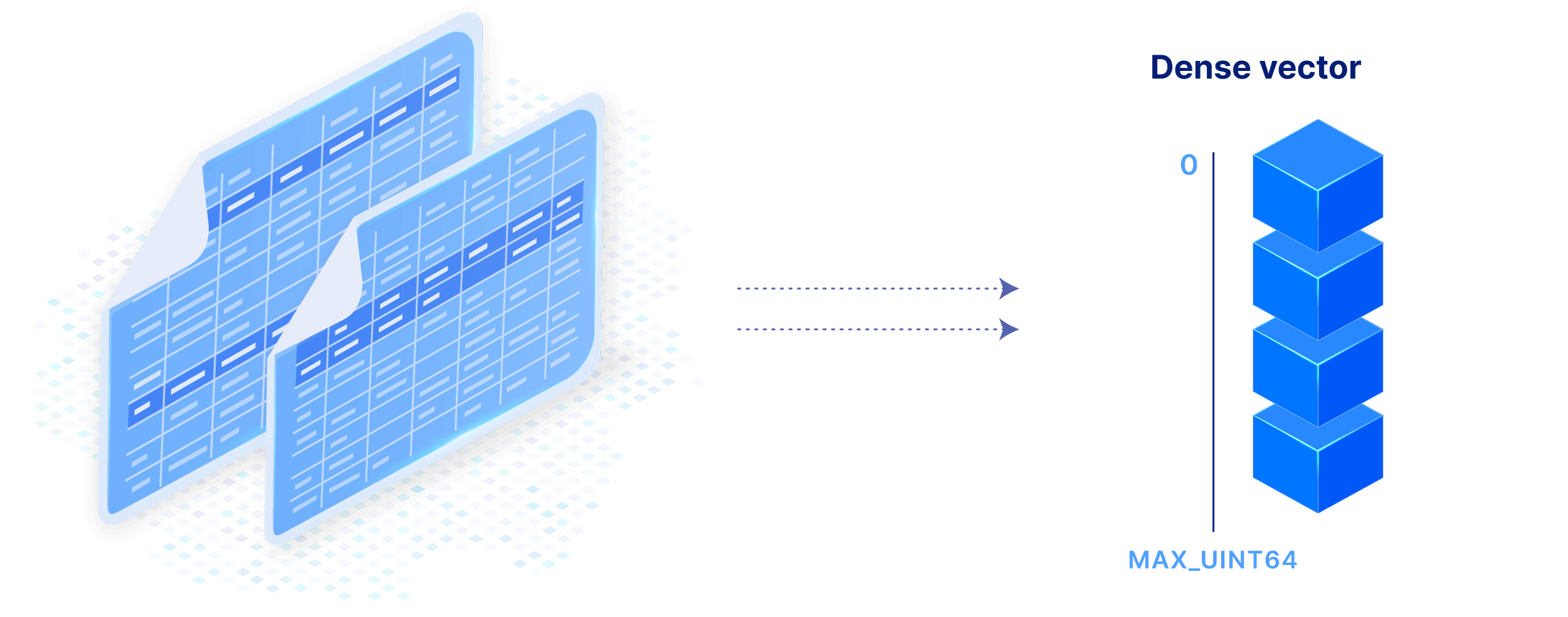
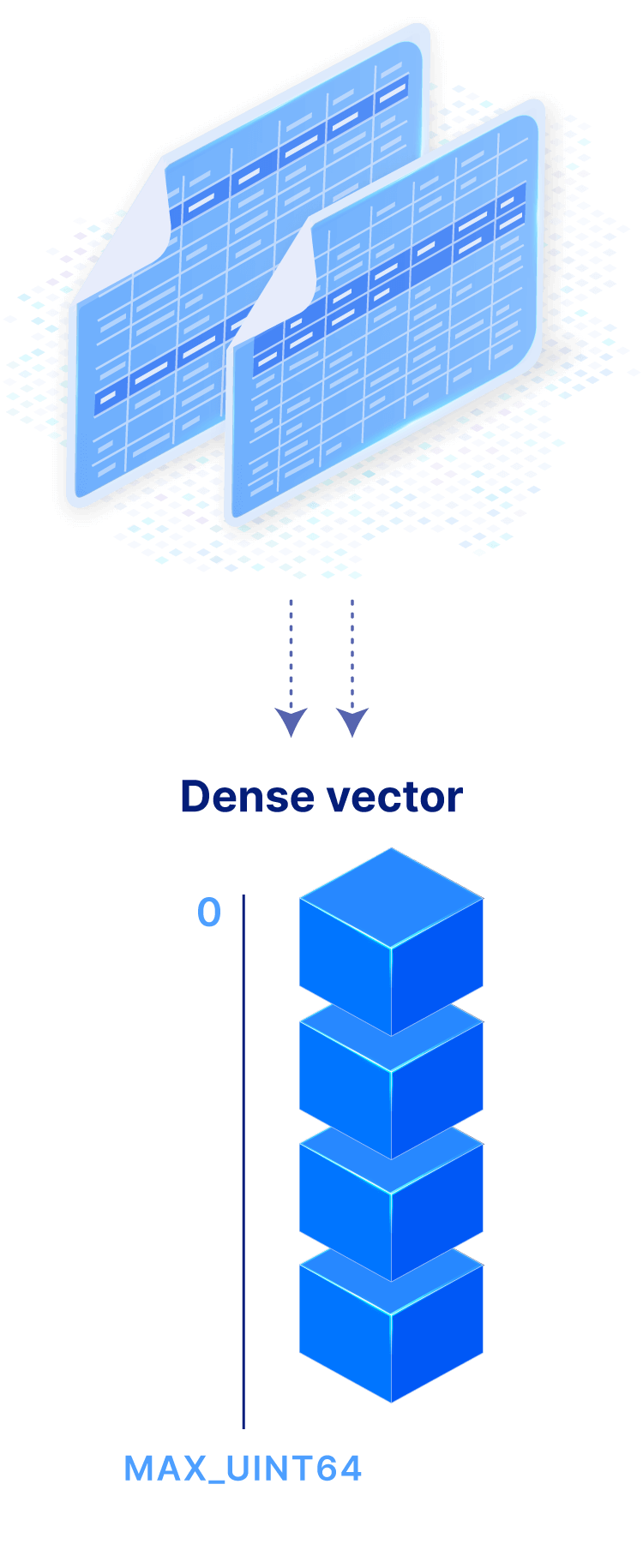
Arrays subsume tables, with multiple data modelings that can be tailored to your application for maximizing performance. Dense vector: Slice on row ID as non-materialized integer dimension.
CAPABILITIES
Superior performance and versatility
Dense and sparse multi-dimensional arrays are able to efficiently capture all types of data, for any current and future data workload.
With the ability to model data using various dimensions, configurable tiling and a variety of layouts on the storage medium, TileDB Embedded is a versatile, yet super performant, storage engine, ideal for any application. TileDB Embedded is currently used in a broad spectrum of industries, including healthcare, telecommunications, defense, finance, earth observation and many more.
INTEROPERABILITY
APIs and integrations
Choose from a growing set of language APIs, popular data science tools and research workflows.
Applications



SQL


Distributed Computing


ML & Data Science





APIs









Diverse storage backendsUtilize various storage backends, from your laptop to a distributed filesystem to a cloud object store, all without any code changes.






# Pip:
pip install tiledb
# Or Conda:
conda install -c conda-forge tiledb-pyUSAGE
One API, N Possibilities
Slicing is the most common operation in TileDB Embedded. Here are some simple examples, using sparse and dense TileDB arrays.

Dataframe, 1D Sparse Array
import tiledb, tiledb.sql
import numpy as np
import pandas as pd
# Assumes we ingested the NYC taxi dataset as a 1D sparse array indexed on
# tpep_pickup_datetime, with the other 17 fields as attributes
A = tiledb.open("nyc_taxi_2019-12")
# Get the fare amount and trip distance for all rides in the
# first two hours of December 1, 2019 in a pandas dataframe
start = np.datetime64('2019-12-01T00:00:00')
end = np.datetime64('2019-12-01T02:00:00')
df = A.query(attrs=['trip_distance', 'fare_amount']).df[start:end]
# Run any SQL query, retrieving the results in pandas.
db = tiledb.sql.connect()
pd.read_sql(sql=
"""
select trip_distance from `nyc_taxi_2019-12`
where fare_amount > 3.0
""",
con=db)
Resource center
 Join the growing TileDB Embedded open-source community on GitHub and shape the future of data management.
Join the growing TileDB Embedded open-source community on GitHub and shape the future of data management.


Documentation
TileDB Embedded is a deep technology. There is a lot more to explore. Get started with our docs and check back for updates.


Forum
Your use cases are shaping TileDB as the universal storage engine. Join the discussions on the TileDB forum.

Join the conversation
We invite you to participate in our Slack Channel. Come up with questions, get answers and become a part of the TileDB Community.