

Table Of Contents:
Introduction
What are multimodal databases?
How do multimodal databases work?
The Benefits of Multimodal Databases
Common Uses of Multimodal Databases
Examples of Multimodal Databases
Multimodal Databases and Multimodal AI
How to Choose the Best Multimodal Database for Your Requirements
TileDB’s Approach: A Multimodal Database for Life Sciences and Beyond
Introduction
In this guide, we will cover multimodal databases, their benefits, and how to choose the best multimodal database for your requirements. We’ve created this guide to be a handy reference about multimodal databases. We will consider the benefits of a multimodal database, its common uses, and touch on multimodal AI. Finally, we will share what to consider when evaluating multimodal databases. Please bookmark this page and share it with colleagues if you find it helpful.
What are multimodal databases?
A multimodal database is a data management system that stores, processes, and retrieves multiple types of data formats within a single unified platform. Unlike traditional databases that handle only structured tabular data, multimodal databases manage diverse data types including text, images, audio, video, sensor data, and specialized data, like genomic sequences. These data types are referred to as multimodal data.
Multimodal databases are often used in healthcare, life sciences, autonomous vehicles, content management systems, and AI and machine learning applications. To choose the best multimodal data platform for your needs, you should consider data type support, scalability requirements, query performance, integration capabilities, and compliance standards.
Modern organizations generate and collect data in numerous forms: structured databases, unstructured text documents, images, audio files, video content, sensor readings, genomic sequences, and time-series data. Traditional database systems manage these different data types in separate, specialized systems. Multimodal databases provide a single platform capable of handling diverse data modalities efficiently.
How do multimodal databases work?
Multimodal databases operate through a flexible architecture that adapts to different data types while maintaining consistent performance and query capabilities. Some multimodal databases, like TileDB Carrara, use multi-dimensional arrays as the foundational data structure, which can shape-shift to accommodate various data modalities efficiently.
When data enters a multimodal database, the system first must identify the data type and apply appropriate storage and indexing strategies. For structured data like tables, the database may use traditional columnar storage with B-tree indexes. For images, it might employ dense arrays with spatial indexing. For genomic data, specialized compression and sparse array structures could be required to optimize storage and retrieval.
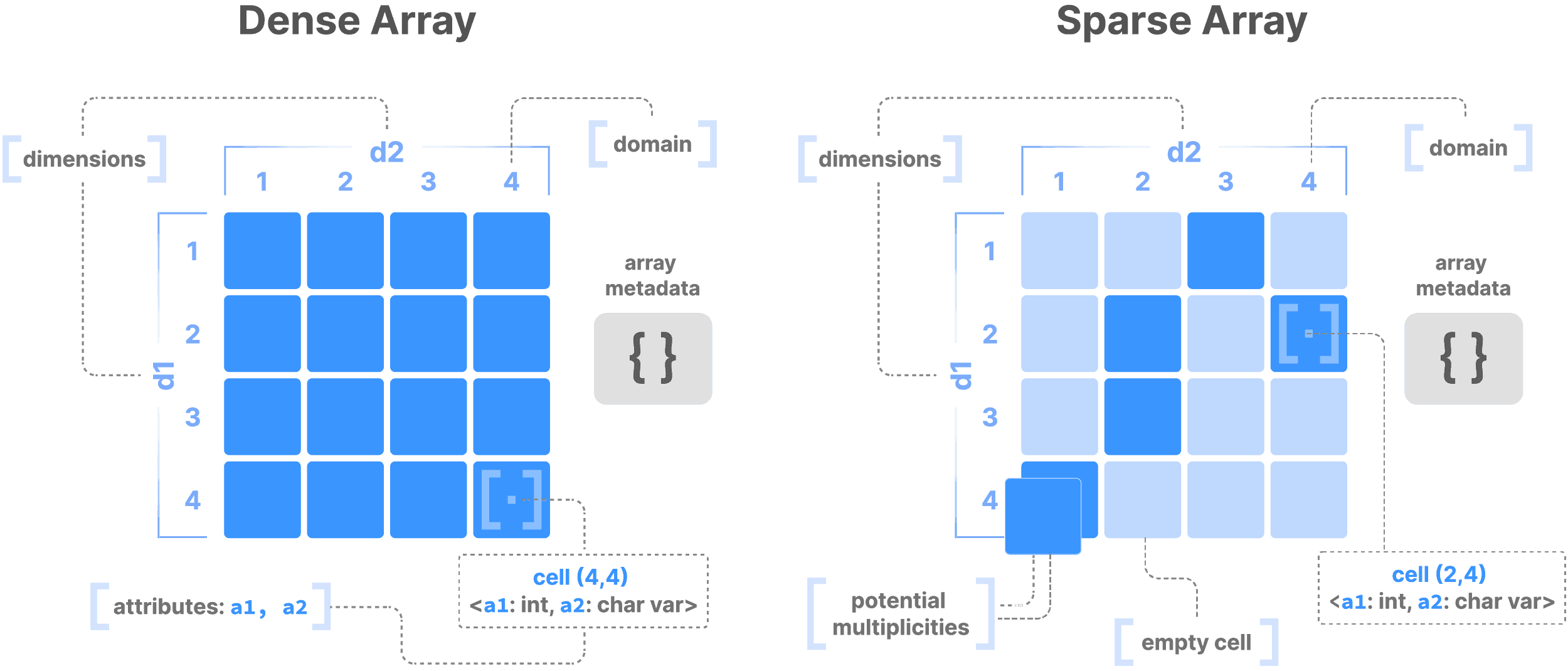
In a dense array, every cell contains a value, which is helpful when you are working with data like images, where each pixel contains information. In sparse arrays, only cells with values are stored, which is ideal for naturally sparse data, like single-cell matrices.
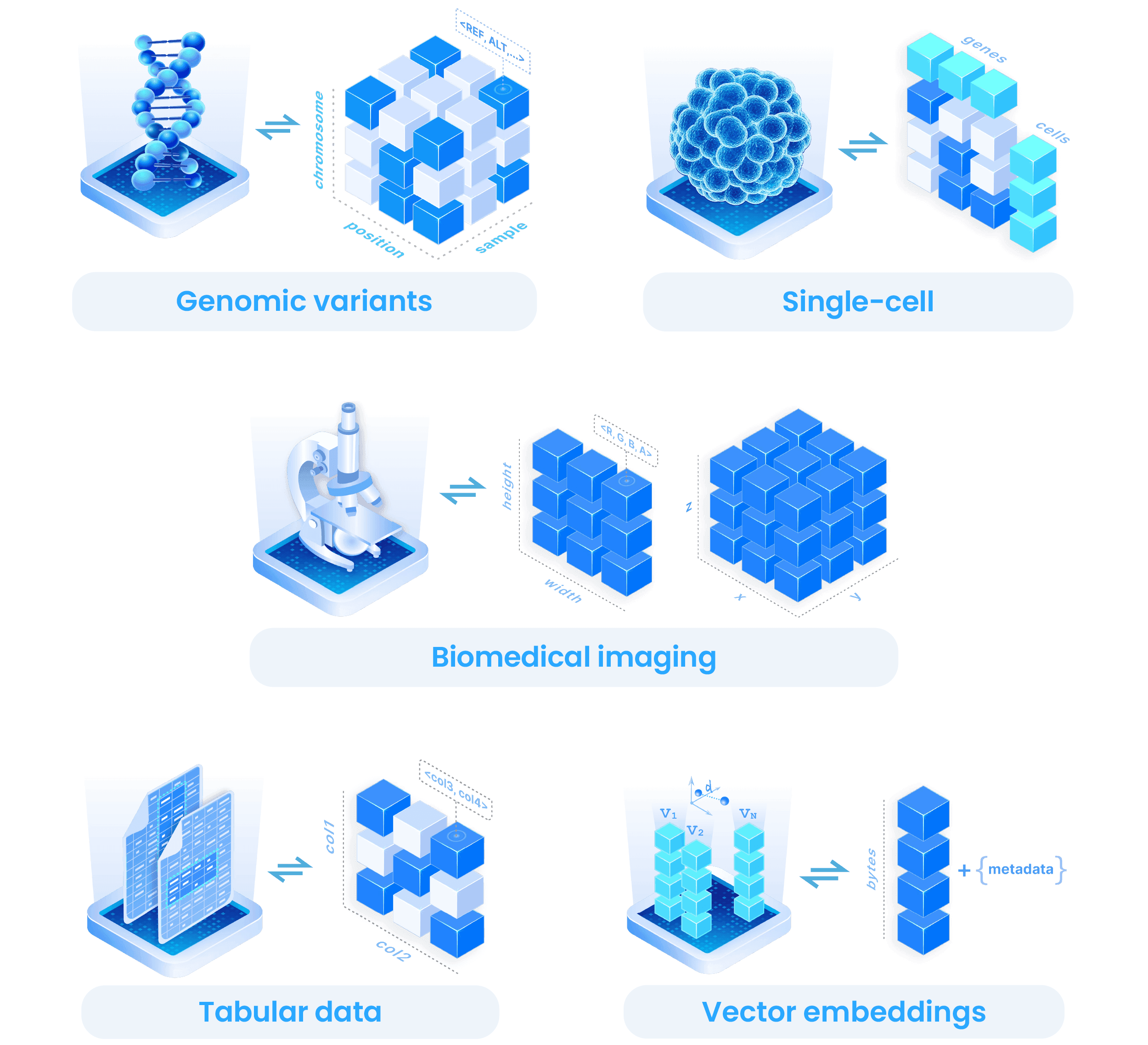
Arrays shape-shift to accommodate diverse data types. For example, genomic variants are modeled as sparse 3-D arrays, representing variant positions and alt/ref alleles. Single-cell data uses the SOMA format, a collection of arrays and groups that capture cell-by-gene matrices. Biomedical images become 2-D or 3-D dense arrays, with attributes for color channels. Tabular data becomes a specialized case of arrays, where dimensions act as indices and attributes store column values. Vector embeddings for AI applications are 1-D dense arrays.
The database should create a unified metadata layer that tracks relationships between different data types and enables cross-modal queries. For example, you could query for all medical images associated with patients who have specific genomic markers in their DNA sequences. The system should handle the complex task of coordinating between different storage engines and index types to deliver results efficiently.
Advanced multimodal databases incorporate machine learning capabilities to understand data relationships automatically and optimize query execution paths based on usage patterns.
The Benefits of Multimodal Databases
Multimodal databases provide significant advantages over traditional single-modality data management approaches. These benefits make them essential for organizations dealing with complex, diverse datasets.
Benefits will vary based on the capabilities of different organizations’ offerings but in general, key benefits of multimodal databases can include:
- 1
Unified data management: Organizations can store and access all their data types in a single system, eliminating the need to manage multiple specialized databases and reducing operational complexity.
- 2
Enhanced analytical capabilities: Cross-modal queries and analytics become possible, enabling insights that would be difficult or impossible to achieve with siloed data systems.
- 3
Reduced infrastructure costs: Consolidating multiple database systems into one platform can reduce licensing, maintenance, and operational expenses and simplify data governance.
- 4
Simplified data integration: Extract, transform, and load (ETL) processes can become more straightforward when more data types can be stored and processed within the same system architecture.
- 5
Better scalability: Modern multimodal databases are designed for cloud-native deployment, offering elastic scaling capabilities that adapt to changing data volumes and query loads.
These advantages translate into faster time-to-insight, reduced total cost of ownership, and improved data governance for organizations across various industries.
Common Uses of Multimodal Databases
Multimodal databases serve diverse industries and applications where organizations need to manage and analyze multiple data types simultaneously. These systems excel in scenarios requiring complex data relationships and cross-modal analytics.
Primary use cases include:
Autonomous vehicles: Storing and processing sensor data, camera feeds, LiDAR point clouds, GPS coordinates, and vehicle telemetry for real-time decision making and training autonomous driving systems
Content management: Digital asset management systems that handle text, images, videos, audio files, and metadata for media companies, marketing teams, and content creators
Financial services: Combining transaction data, customer documents, risk models, market data feeds, and compliance records for comprehensive financial analysis and regulatory reporting
Healthcare and life sciences: Managing patient records, medical images, genomic data, clinical trial information, and research datasets in unified platforms for comprehensive patient care and drug discovery
Manufacturing and the Internet of Things (IoT): Integrating sensor readings, equipment logs, production data, quality control images, and maintenance records for predictive maintenance and process optimization
Scientific research: Managing experimental data, publications, instrument outputs, simulation results, and collaborative research across disciplines like astronomy, climate science, and materials research
These applications demonstrate how multimodal databases enable organizations to break down data silos and gain holistic insights across their entire data ecosystem.
Examples of Multimodal Databases
Several database platforms exemplify the multimodal approach, each with distinct strengths and target applications. These systems demonstrate different architectural approaches to handling diverse data types.
TileDB stands out as a multimodal database specifically designed for scientific and complex data workloads. It uses shape-shifting multi-dimensional arrays to efficiently structure everything from tabular data to genomic variants, biomedical images, and vector embeddings. TileDB excels in life sciences applications, handling single-cell transcriptomics, population genomics, and biomedical imaging with unprecedented performance and scale.
MongoDB offers document-based storage with support for various data types including JSON documents, binary files, and time-series data. Its flexible schema design makes it suitable for content management and application development scenarios.
Amazon Neptune provides graph database capabilities alongside support for different graph models and query languages, making it suitable for knowledge graphs and recommendation systems.
Apache Cassandra handles time-series data and large-scale distributed scenarios, often used in IoT and analytics applications, where massive data volumes and high availability are critical.
Elasticsearch combines full-text search with structured data storage, enabling complex search and analytics across documents, logs, and structured datasets.
Each platform takes a different approach to the multimodal challenge, with TileDB specifically architected for scientific computing and complex analytics workloads that require high-performance access to diverse data types.
Multimodal Databases and Multimodal AI
Multimodal databases serve as the foundation for multimodal AI systems that process and analyze multiple data types simultaneously. These databases provide the unified data access layer that modern AI applications require to train models on diverse datasets and to deliver intelligent insights.
Multimodal AI systems rely on the ability to correlate information across different data types. The use of multimodal data in healthcare is common. For example, a medical AI system might analyze patient imaging data alongside genomic information and clinical notes to provide comprehensive diagnostic insights. The database must efficiently store and retrieve all these data types while maintaining the relationships between them.
Vector embeddings represent a crucial connection point between multimodal databases and AI systems. These databases can store and index high-dimensional vectors generated by machine learning models, enabling similarity search and recommendation systems across different data modalities.
AI applications that rely on streaming data, or data that flows continuously from the real world into a database, particularly benefit from multimodal databases. Autonomous vehicle systems exemplify this need, requiring immediate and simultaneous access to sensor data, maps, traffic information, and vehicle telemetry to operate vehicles safely and to ensure they reach their destinations.
The integration between multimodal databases and AI frameworks continues to evolve, with databases increasingly offering native machine learning capabilities and AI-optimized data access patterns that accelerate model training and inference workflows.
How to Choose the Best Multimodal Database for Your Requirements
Selecting the right multimodal database requires careful evaluation of your specific requirements, data characteristics, and organizational constraints. The decision impacts long-term scalability, performance, and total cost of ownership.
Start by cataloging your data types and understanding their characteristics. Consider volume, velocity, variety, and the relationships between different data modalities. Evaluate your query patterns and performance requirements for each data type. Some databases excel at certain workloads while being adequate for others.
- 1
The database should be a central system of record that can support routine and emerging data types and can automate your data pipelines. The key here is having capabilities that connect, not move, your data. For life sciences applications, it’s important the database abides by FAIR data principles.
- 2
Assess scalability requirements both for data volume growth and concurrent user access. Cloud-native solutions often provide better elasticity, while on-premises deployments may offer more control for sensitive data scenarios.
- 3
Consider integration capabilities with your existing technology stack. APIs, programming language support, and compatibility with analytics tools influence development productivity and maintenance costs.
- 4
Evaluate vendor support, community ecosystem, and long-term viability. Open-source solutions provide flexibility but may require more internal expertise, while commercial platforms offer professional support and managed services.
- 5
Security and compliance requirements significantly impact platform choice, especially in regulated industries like healthcare and finance. Ensure the database meets your specific governance standards for user access and controls and provides necessary security features.
- 6
Budget considerations should include not just licensing costs but also operational expenses, training requirements, and migration costs from existing systems.
[begin inline CTA]
Looking for a multimodal database for the life sciences? Check out our 2025 Buyer’s Guide for Multimodal Data Platforms.
[end inline CTA]
TileDB’s Approach: A Multimodal Database for Life Sciences and Beyond
TileDB provides a multimodal database designed for life sciences and scientific computing applications. The platform addresses the unique challenges researchers face when working with complex biological and medical data that span multiple modalities and scales.
Life sciences organizations generate diverse data types, including genomic sequences, single-cell transcriptomics, proteomics, biomedical images, clinical trial data, and research publications. TileDB's array-based architecture efficiently structures all these data types while providing the performance needed for large-scale scientific analysis.
The platform's SOMA (Stack of Matrices, Annotated) Python Project, specifically addresses single-cell genomics workflows, while its VCF support enables population-scale genomic variant analysis. Biomedical imaging capabilities handle multi-resolution microscopy data, and the integrated vector search functionality supports AI-driven drug discovery applications.
TileDB's cloud-native design and serverless architecture align with modern research collaboration needs, enabling secure data sharing while maintaining compliance with regulations like HIPAA. The platform's distributed computing capabilities handle the massive computational requirements of genomic analysis and machine learning workloads common in life sciences research.
TileDB Carrara introduces new capabilities that allow unified data discovery, streamline data organization, analysis, and collaboration, particularly for teams working with complex multimodal data.
Ready to transform your life sciences data management? Schedule a discussion with a TileDB team member to discover how TileDB can accelerate your research and unlock new scientific insights with unified multimodal data analysis.
Meet the authors
