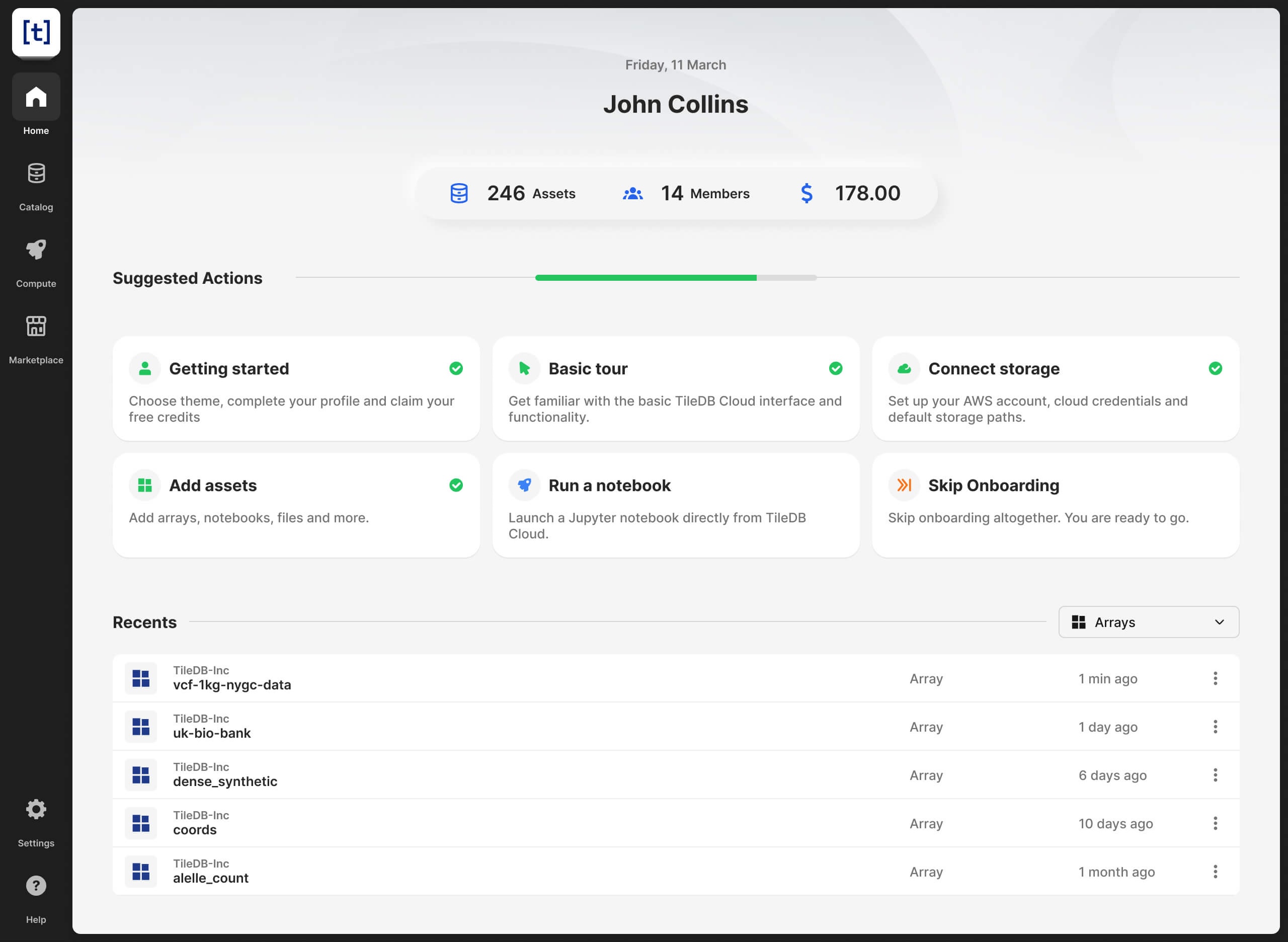
TILEDB CLOUD
The ultimate data platform
Manage, collaborate, scale.
Consolidate the modern data stack with one platform for all modalities, code and compute.
Get started - for free
UNIVERSAL
One solution for all data
TileDB Cloud employs a modern database design that optimizes the analysis of all data types, for all applications. Manage tables, images, video, genomics, ML features, metadata, even flat files and folders — all in a single powerful solution based on multi-dimensional arrays.

PERFORMANT
Everything is an array
TileDB Cloud uses the open-source TileDB Embedded storage engine, which stores all data as multi-dimensional arrays, the currency of data analytics. This canonical array format adapts to data of any shape and size, enabling superior performance tailored to any application workload.
Learn more




VERSIONED
Version all data assets and time travel
Get data versioning and time-traveling out of the box. Versioning capabilities are built into the TileDB array format itself, allowing all data and code assets on TileDB Cloud to inherit these properties. Quickly browse different versions of your assets in the TileDB Cloud console, or access them programmatically in the language of your choice.


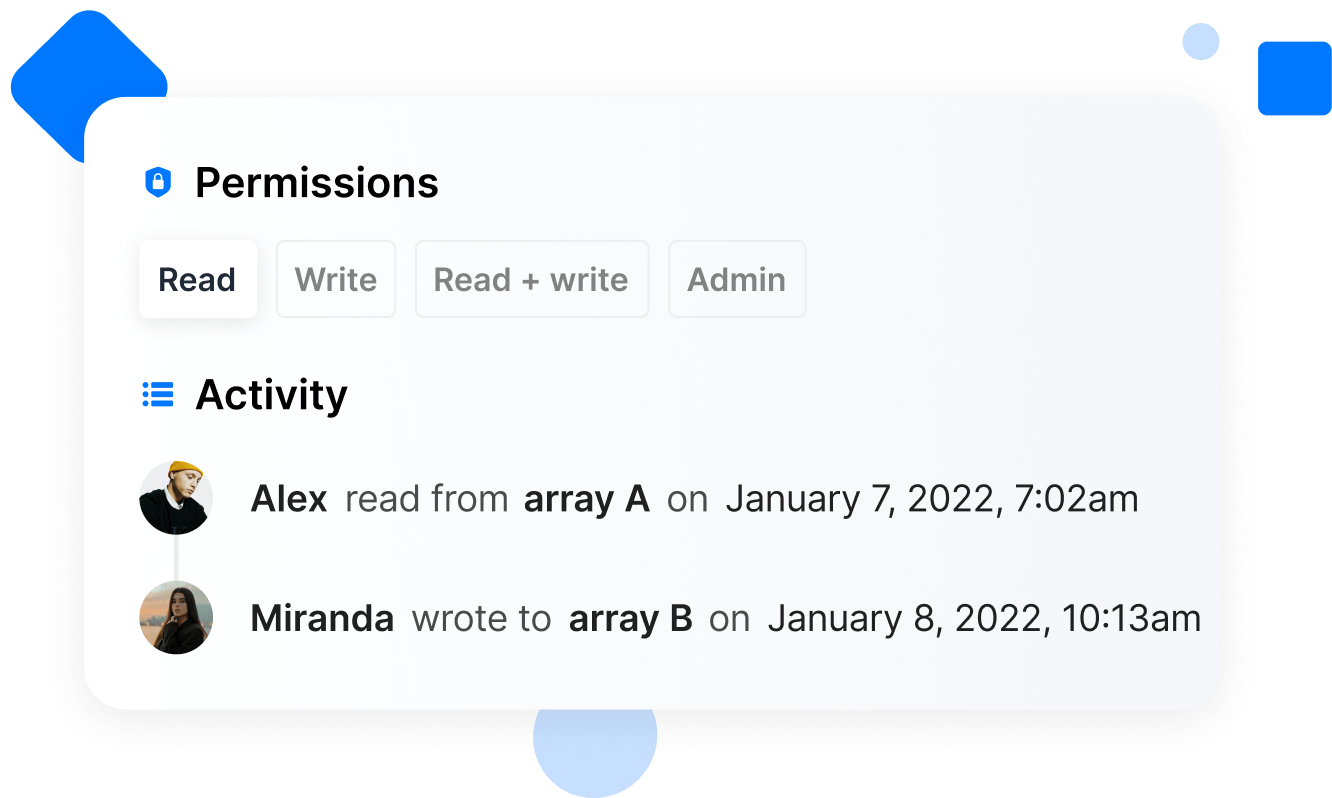
 CONTROLLED
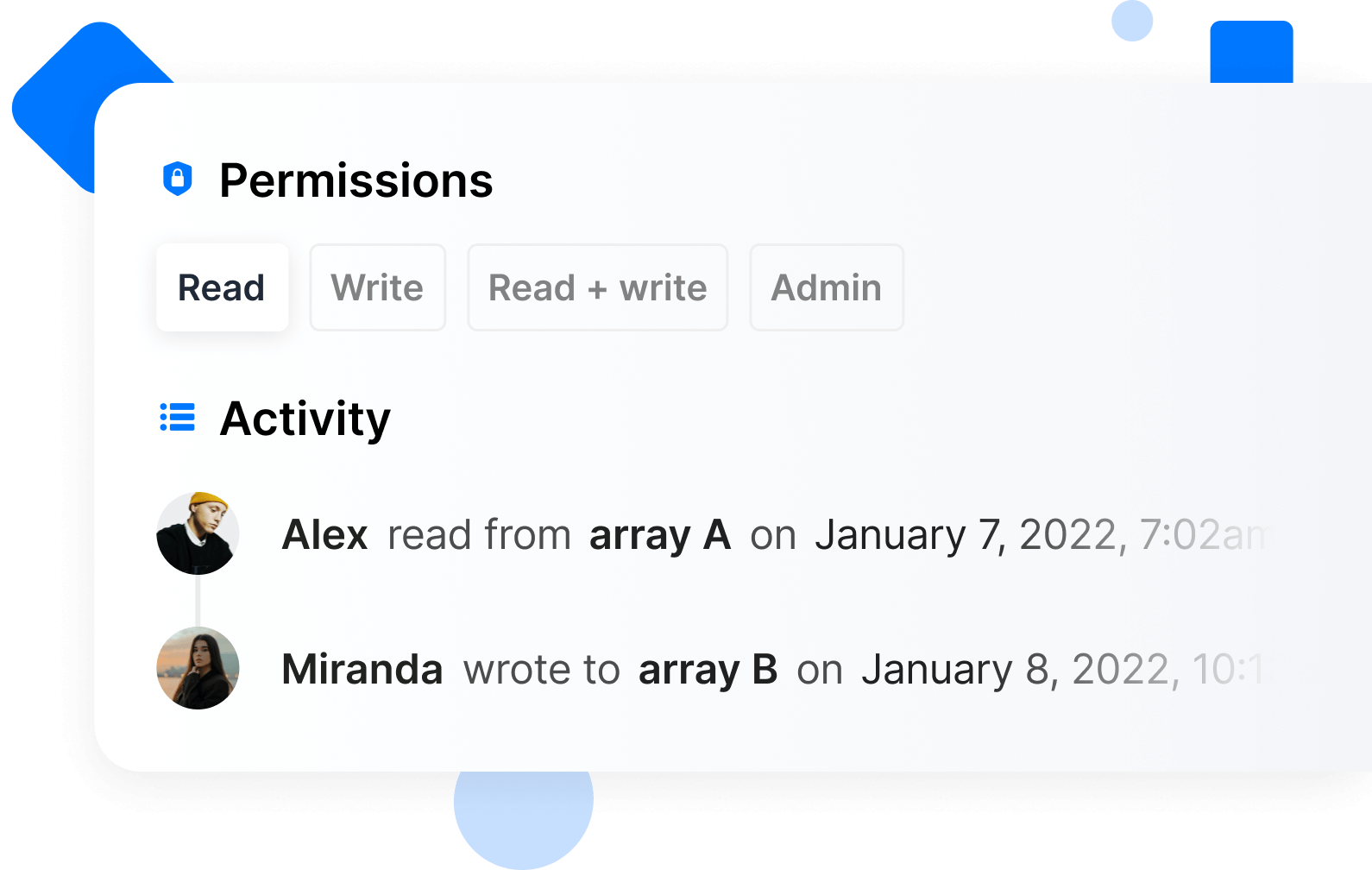
CONTROLLEDSecure governance
Control and monitor all access. Define access controls and securely share any data asset. Centralize permissions management and billing using TileDB Cloud organizations. Hierarchically organize assets into TileDB groups to simplify collaboration on large projects. All access and compute are logged for detailed data governance and compliance.
INTEROPERABILITY
Use your favorite tools
TileDB Cloud interoperates with your existing workflows, with numerous APIs, support for popular machine learning frameworks, and domain-specific integrations.
Applications



SQL


Distributed Computing


ML & Data Science





APIs









Efficient APIs and tool integrations with TileDB via zero-copy techniques



 Jupyter Notebooks
Jupyter Notebooks
Create, launch and share notebooks on TileDB Cloud


ML Models
Build and scale ML models
Centrally manage ML models alongside the data and code used to train them. TileDB Cloud automatically versions models for efficient collaboration and exposes metadata directly for fast exploration and search. Share and scale your work with support for popular frameworks like PyTorch, Tensorflow, Keras and Scikit-Learn.


Dashboards
Visualize your data
Expose your work to a wider audience. The same notebooks that power your research workflows can publish data visualizations to the web as interactive dashboards. Dashboards are a dedicated asset type in TileDB Cloud and are shareable from the TileDB Cloud console.
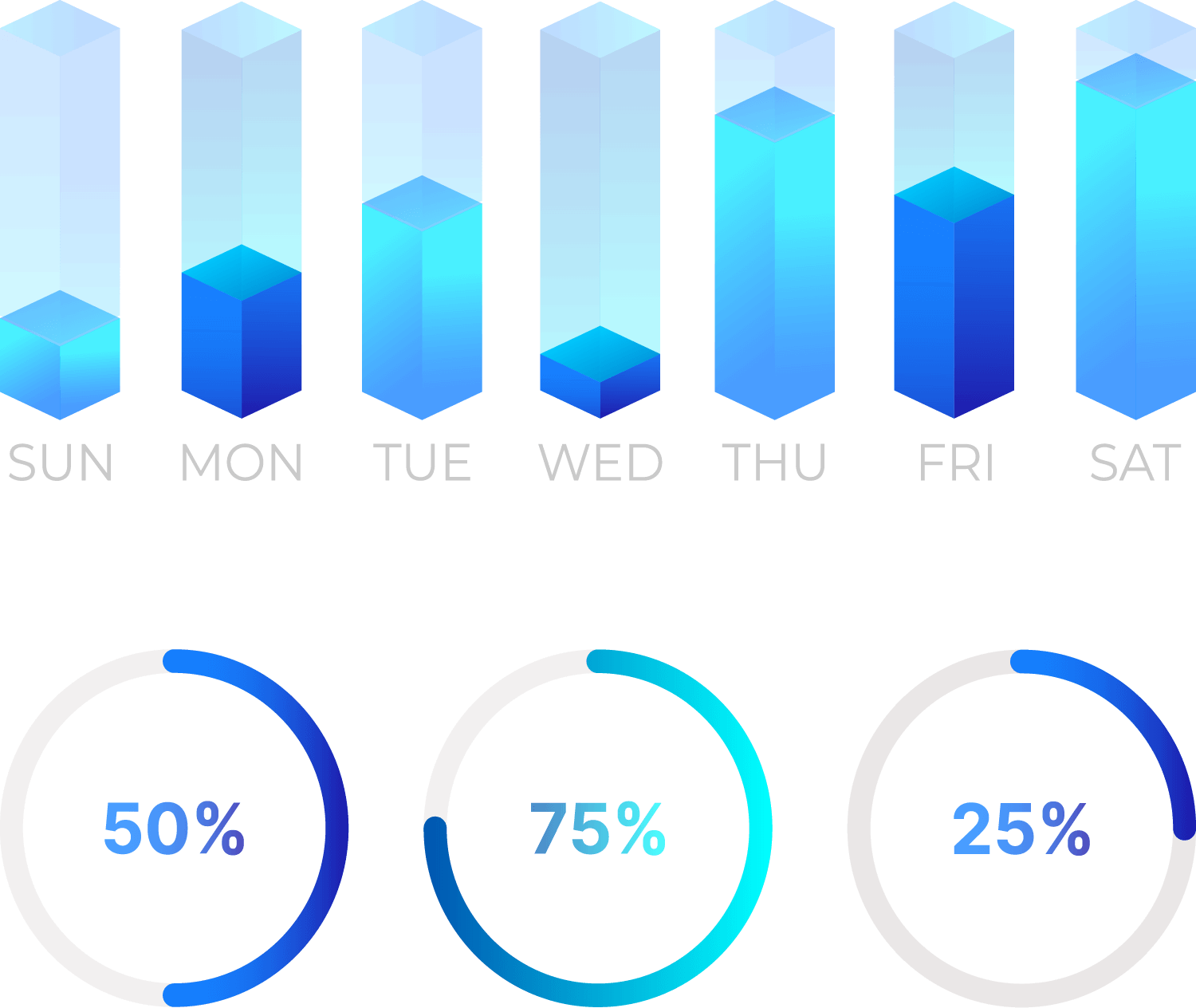

Scalable Compute
Serverless SQL & UDFs
Compute on large datasets, without expensive clusters. TileDB Cloud moves computations closer to your data, automatically scaling based on code execution and minimizing egress by reducing the size of results. Aggregation queries are especially effective, along with compute push-down into the storage engine. TileDB Cloud supports serverless SQL and serverless UDFs in Python and R.


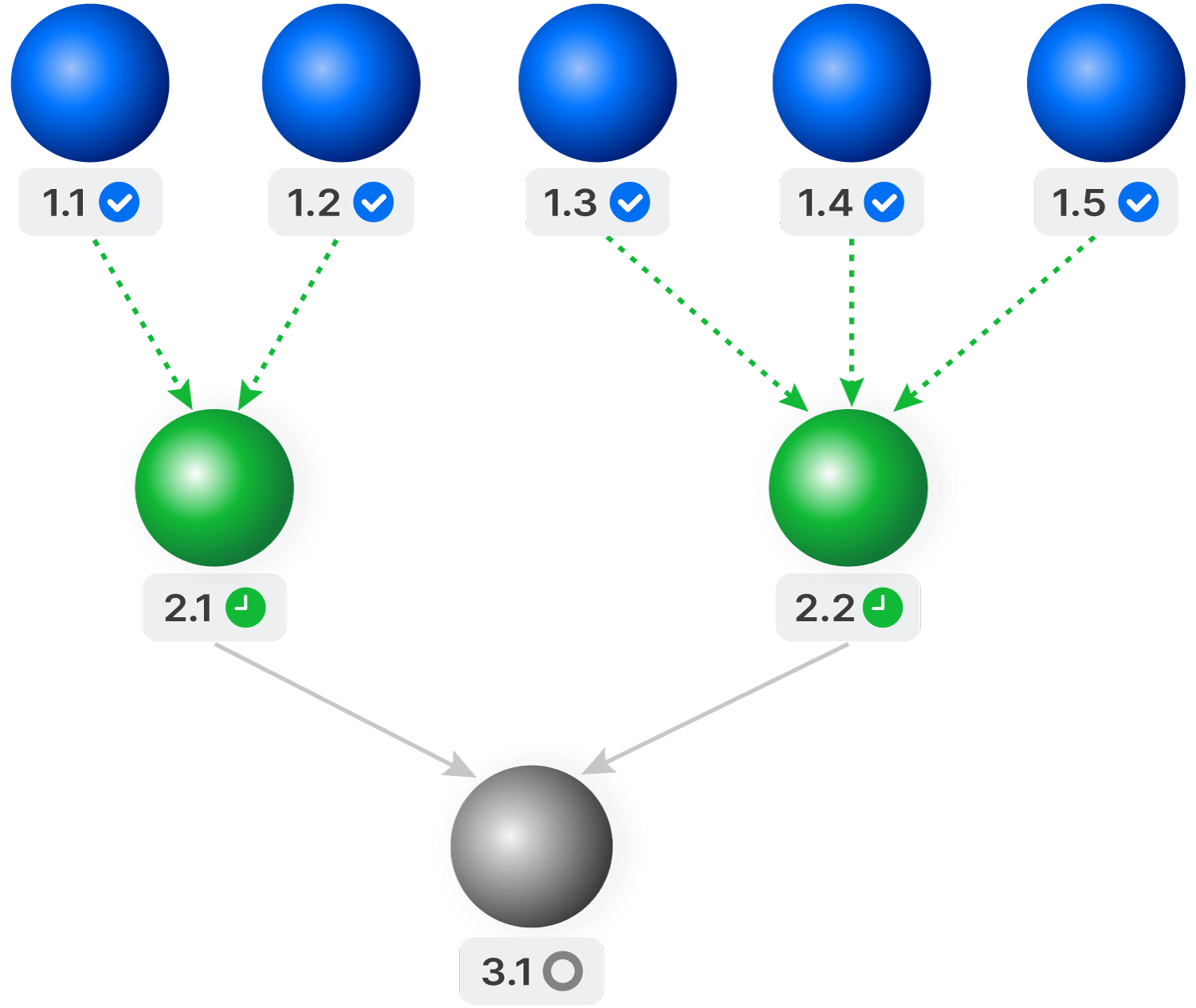
Task Graphs
Parallelize execution
Combine basic actions, like slicing and SQL, with UDFs to build any distributed algorithm. Easily order complex operations as a directed task graph. Programmatically dispatch task graphs, or use TileDB Cloud’s Jupyter environment to create and execute them. TileDB Cloud parallelizes execution in a serverless manner, while respecting the dependencies at each stage and monitoring all progress.

Secure sharing
Discover, contribute & collaborate
Automatically catalog datasets, code, and associated metadata for advanced discoverability and governance. TileDB Cloud offers access controls so you can easily grant and manage permissions. Version your work, including notebooks and ML models, and securely share them with internal teams and external partners.
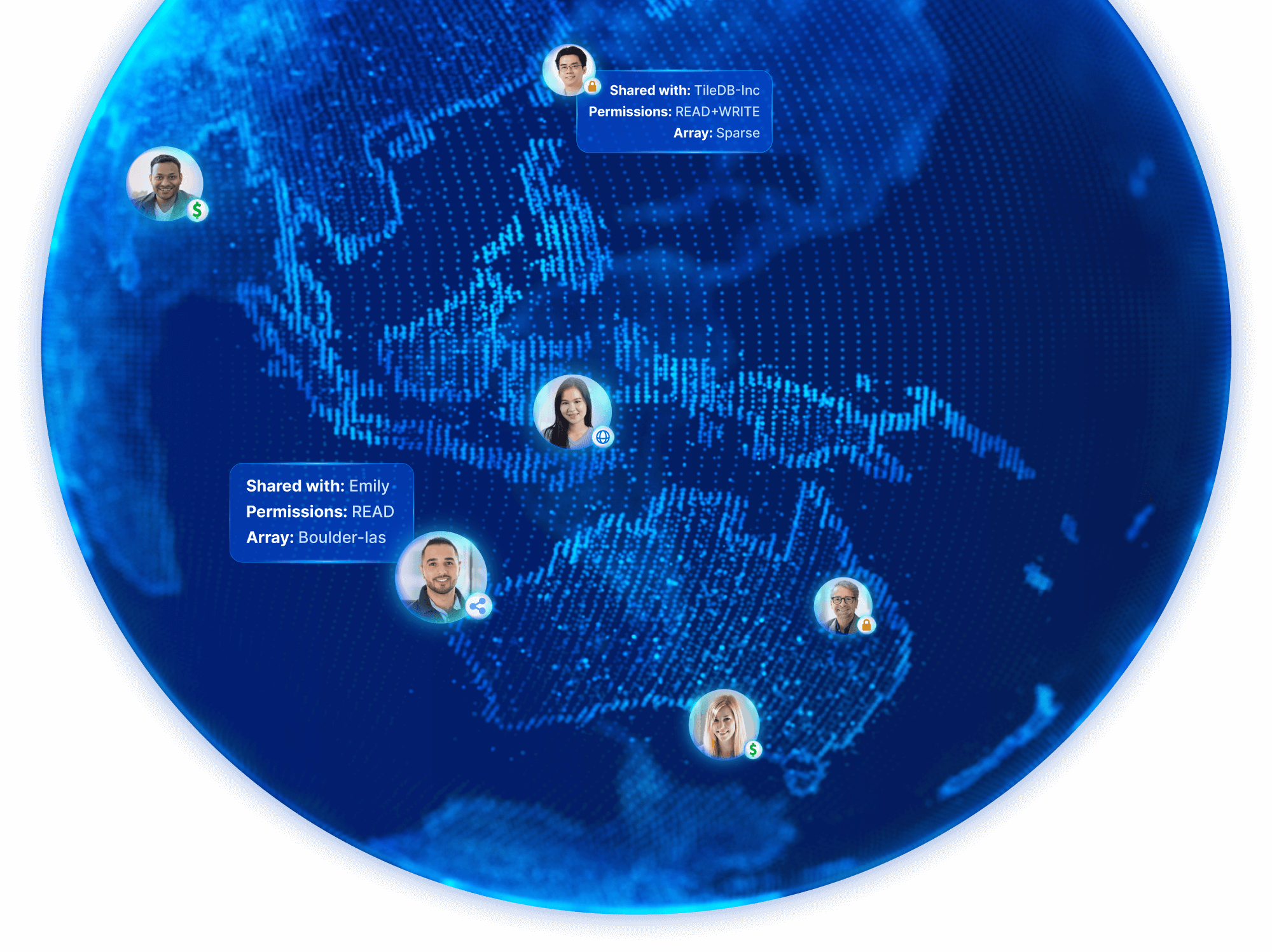

Monetization
Discover, contribute & collaborate
Sell proprietary data, code and more, with no additional infrastructure or cost. Built-in payment and marketplace features allow you to develop derived data products and monetize them in a new economic model that accommodates data producers and consumers alike.